
Netflix Recommendation List
Netflix, one of the world’s biggest provides of movies and tv shows, is no stranger to machine learning algorithms. In 2009, they gave away the biggest prize ($1,000,000!) for improving a movie recommendation algorithm. Although Netflix is great at movie recommendations and unsupervised algorithms to determine those movies, they have not been collecting much data on the top movies of all time. In this project, we will try to find which factors contribute the most to pushing a movie to the top of the list and making the IMDB Top 250.

Problem
We would like to see what makes a movie highly rated. We know a movie can have several factors (Plot, Director, Year it was released, etc). Perhaps some of these factors matter more than others. Let’s find out!
Data & Resources
I used OMDB, a useful API for querying the info on a single movie. In order to get the movie titles, I web scraped imdb for 1,500 random movies that had imdb rating from 0 to 10. Here’s a plot of my distribution of movies and their ratings:
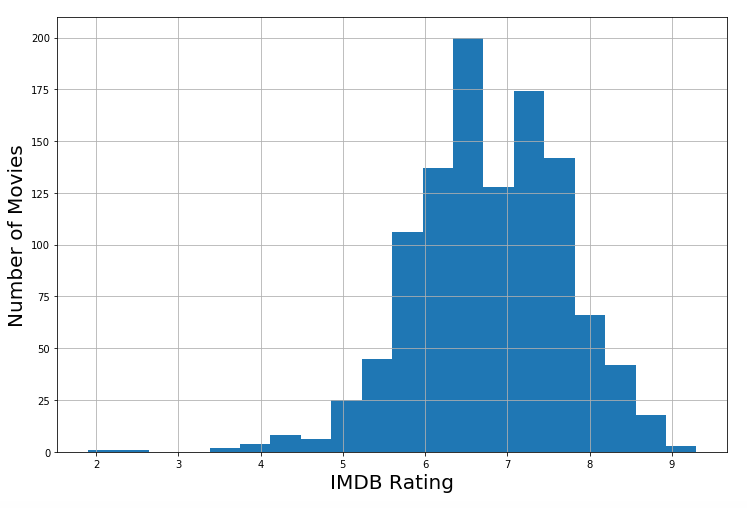
As you can see, it is normally distributed with 2 outliers in the 2-3 rating. I decided to leave these in to maintain variation. After dropping null values and excluding non-movie results, I ended up with roughly 1000 movie results. Not bad.
Feature Selection
I decided to drop a few columns (listed in the jupyter notebook link at the bottom of this page) because many of them had no variation. For example, all the values of “Country” were in United States, and “Type” was all movie type. Also, one of the values was highly correlated with the target variable (imdb rating). I decided to drop this value as well. In the end, we are left with plot, director, votes, year it was released, actors, writers, awards, genre and NC rating.
Feature Engineering
After acquiring all the necessary features, we needed to dummify and standardize the variables. I took the 20 most common directors, lead actors, and writers, and dummified them. For the plot and title, I took the 100 most common words and dummified those as well. I dummified NC rating as well.
I used regex in order to get the amount of Oscars, wins, and nominations. I standardized these values, along with the year the movie was released. Finally, after dummifying and standardizing all the features, I threw the data into models.
Models
We stuck with tree-based models for this project. I used Decision Trees, Bagged Decision Trees, Random Forest, and Extra Trees. Out of all the models, Random Forest outputs the best accuracy with 0.47, which isn’t too good. However, after splitting the data into a train-test split and fitting the train data on a Random Forest model, I was able to increase accuracy to 0.596, which is a bit better. I plotted my prediction with the actuall values here:
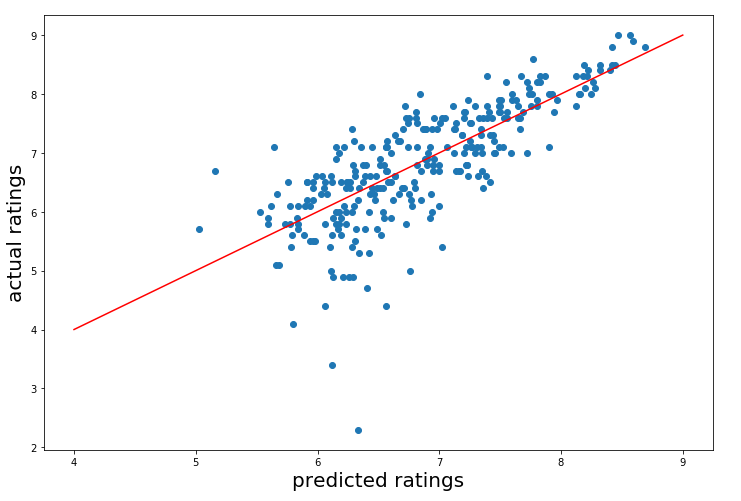
My Random Forest model accurately predicted movies of high ratings, but wasn’t that good at predicting low rated movies. This was due to the fact that the majority of my movie dataset ranged from about 5-10, and wasn’t able to train as much on lower values. In this case, it would’ve been better to drop the low-rated outliers, but that is not feasible in real-world situations where there will most likely be very low-rated movies. Another way you can improve the accuracy would be to add a boost, such as XGBoost or Adaboost.
Important Features
Here’s a chart of what I found to be the most important features for determining a movie’s popularity.
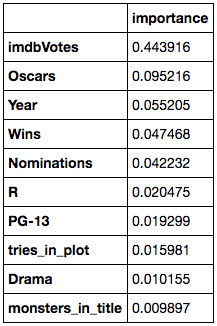
These finding are not surprising, as it’s obvious that most people will vote for their favorite movie, and not really care about taking the time to vote on bad movies. This means that rating is highly correlated with number of votes. Also, the amount of awards the movie recieved were a good measure of imdb rating.
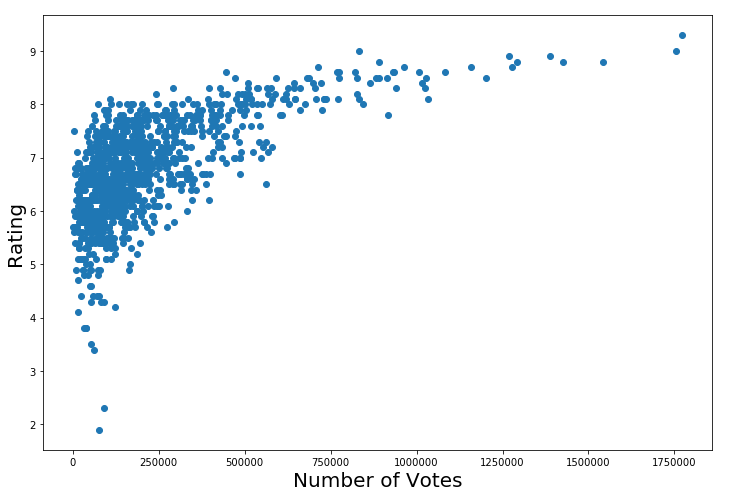
There is one very surprising fact that I found. The year a movie was released was the 3rd most important feature. After looking into it, here’s a graph plotting rating against year:
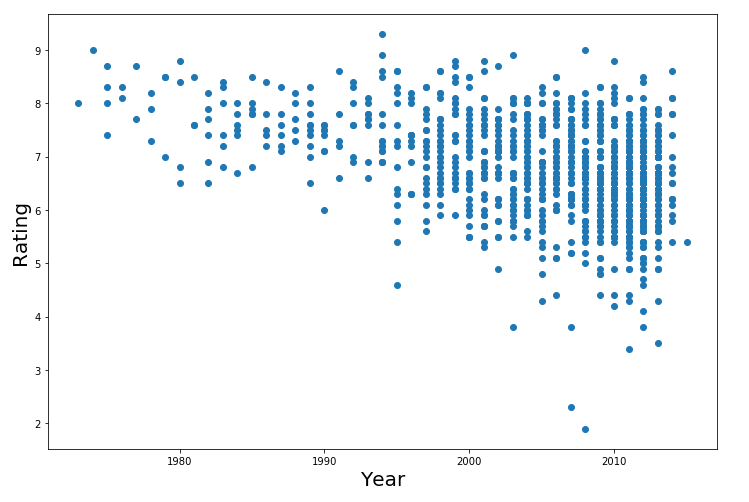
There’s a definite curve associated with more recent movies. After doing research, I discovered that IMDB was founded in 1990, which is the exact year when ratings start to vary, and we get lower rated movies. This is due to the fact that people adore classic movies, and are more critical of recent movies. For example, compared to today’s standards of CGI, Star Wars would pale in comparison to current movies. However, people rated it very highly out of nostalgia and the ground-breaking effect it had on the movie industry at the time.
Conclusion
My recommendation for Netflix would be to add the movies that attained the most awards and the ones that had the most votes on IMDB. It also seems that people like classic movies that take them back to a sense of nostalgia. It’s why we watch re-runs of our favorite shows and it never gets old.
In addition, I would recommend using the customer’s age as a guage of which movies they feel nostalgic towards. Certainly a person born in the 70’s will have grown up on different movies than a person born in the 90’s.
Please check out the original code in my jupyter notebook here