
Estimating Data Scientist Salaries
Finding the optimum salary in which both employee and company can agree on is a necessity in any job market. We will apply our knowledge of web scraping and logistic regression to come up with a model that correctly predicts what a data scientist’s salary should be based on the job results of Indeed.com.
The Data
I webscraped 50,000 pages of Indeed to find job results that provide location, reviews, job title, job description, and most importantly salary. Indeed says that only 20% of their jobs actually have salaries. However, I was only able to get 191 job results that met all criteria. Thus, the most limiting drawback of the data was the amount of data. Due to the limited number of rows, I decided to scrape the entire United States by each State that it could expand my search. However, that only yield a few more results. 191 jobs will have to suffice for training and testing.
My Hypothesis
In addition to getting all the data and creating a model, I decided to see if there was any significance to average word length in the description. My hypothesis was that jobs with bigger words equated with bigger salaries. I found the average word length and plotted it to get this graph:
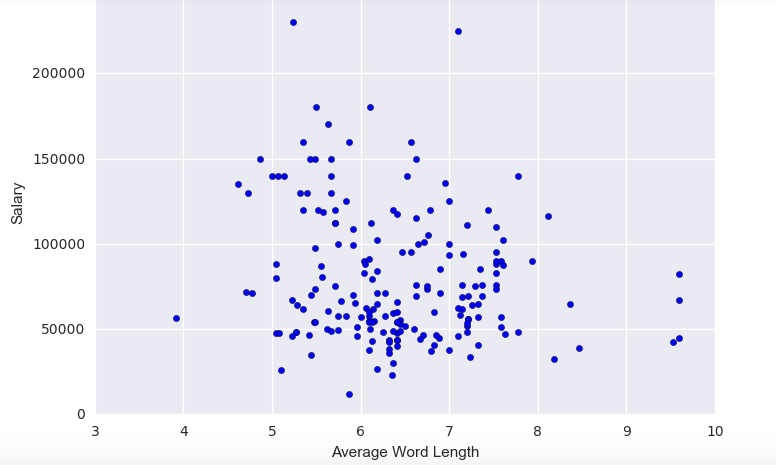
As you can see, there is no relationship between average word length and salaries. In fact, salary tended to decrease as the word lengths increased. I assume that maybe some jobs try to use bigger words to make the job seem a bit more important even though it has a smaller salary. I must reject my hypothesis.
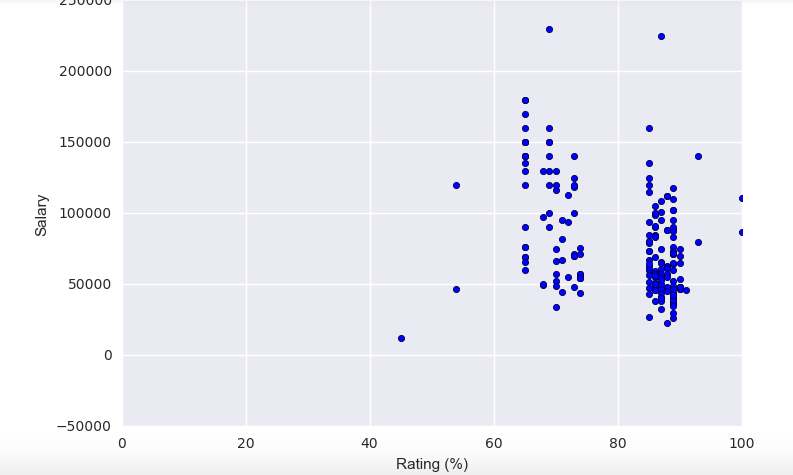
The graph above also shows no relationship between salary and ratings. However, very low ratings equated to lower salaries.
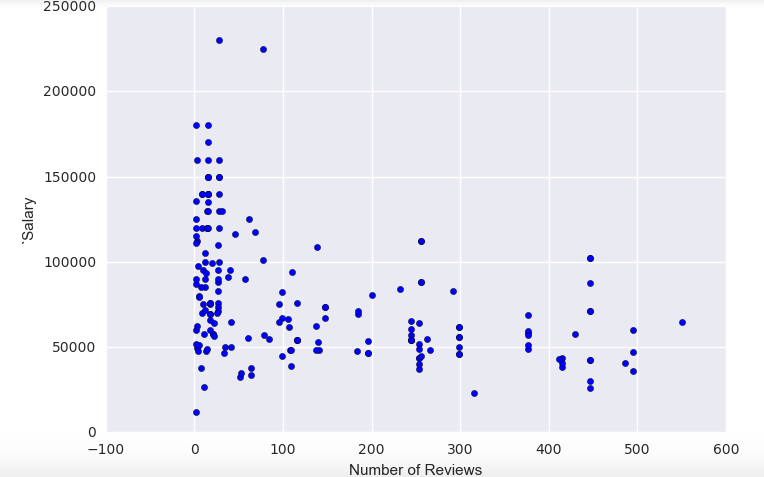
The graph above shows that the number of reviews also did not affect salary.
The Model
We are using logistic regression to predict salaries. This may seem counterintuitive since salaries are a continuous value. However, it is much more useful to give ranges of salaries in order to make room for negotiation and possibly other factors that affect salary. We built the model and found the features that affect the salaries the most. In my case, it was the words “data” and “research” that had the most effects. If “data” was in the job title, then it came with quite a big average salary of $117,000. However, if “research” was in the job title, then the average salary was roughly $ 56,000. This makes sense because most research jobs get paid very little. Neither reviews nor job description had any particular impact on salary.
I also wanted to find the average salaries of data scientist jobs in each state. I found the best states with top salaries to be Delaware, New Mexico, California and Massachusetts. However, it is very important to note that I was only able to scrape very few jobs for each state (less than 10). So this data is hardly representative of an entire to state, let alone the country.
Now let’s go over the confusion matrix:
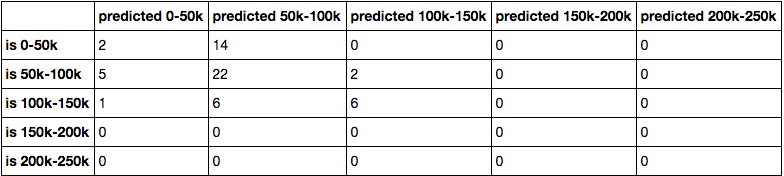
I found my accuracy, precision, recall and F1 scores to be quite terrible due to the lack of data to train on. The accuracy was about 52%, precision at 50%, recall at 52%, and F1 at 48%. This means that we have roughly a 50:50 chance of predicting the correct salary, which is about the same as a coin toss. There was also a high concentration of data points in the 50k-100k range as shown below:
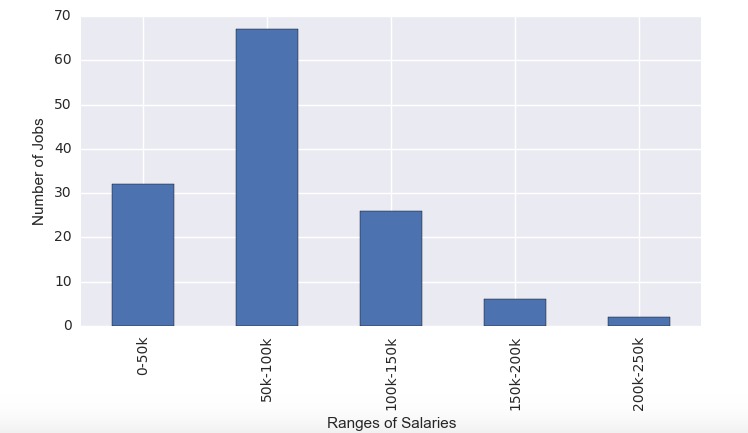
Thus, the model couldn’t train much on other salary ranges. The model also tended to overpredict the $0 - $50,000 salaries with values between $50,000 - $100,000. This is a very bad idea since it discourages employees that thought they were getting a bigger salary.
Conclusion
So in conclusion, we should judge the salaries based on the title and location of the jobs. Jobs with “research” in the title should get paid lower pay (around $50,000) and jobs with “data” in the title should get paid more (around $100,000). As for location, jobs in Delaware, New Mexico, California and Massachusetts will pay very well. Here’s a map to show data science salaries across the United States:
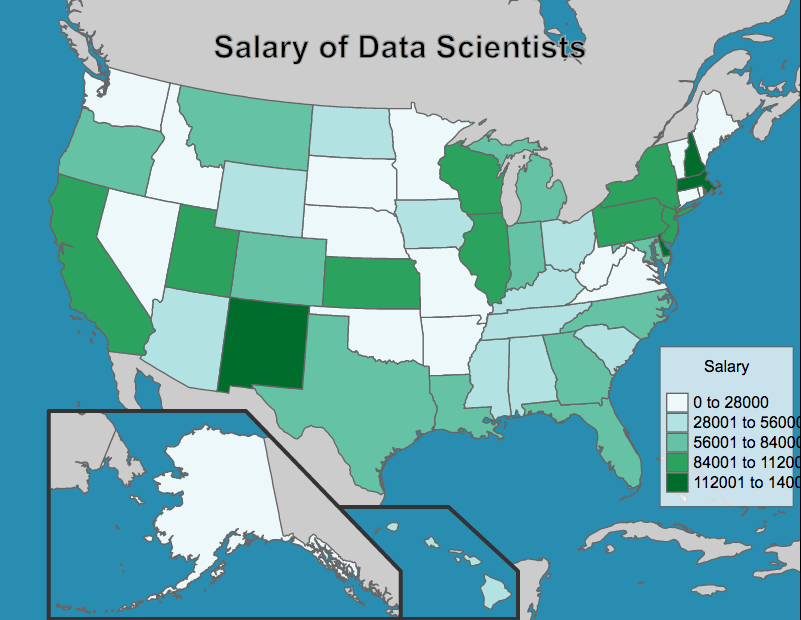
Please check out the original code in my jupyter notebook here